A Google Sheet Addon that classifies your expenses
Using a machine learning model

In my last post on this series, I ended up wanting to explore Google Sheets as an add-on. Kind of like Tiller lets you integrate into your bank account.
If you’re starting, here is a summary:

Every month I export a bunch of transactions from credit card/bank accounts and want to know which category they fall into. I’m really happy with my current process. It’s rules-based, meaning that I’ll define something like *Coles* = Groceries i.e. if it finds Coles in the description, it sets the category to groceries.
The problem. Well, if it’s your first time at KMART, you’ll have to set up a new rule.
Sounds like AI could help, so I started using some language models and built this custom app (details here).
The basics
The basic process is important to understand. You train your old expenses and use them as a reference for new expenses. If there’s a match, assign the category of old to new. Simple, right?
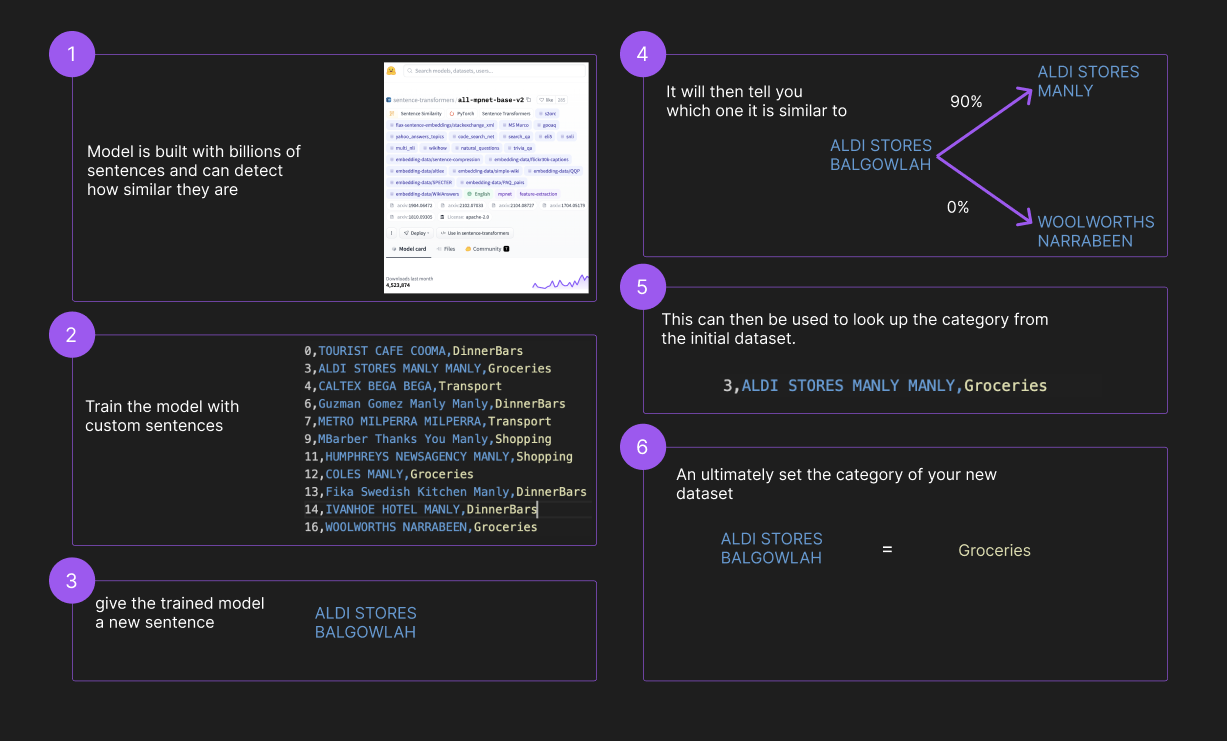
The tricky part is done with a machine learning model. The sentence transformer model. It turns a sentence, such as our expense description, into a numerical format. This is called embedding and allows understanding of the meaning of the sentence.
If you have the meaning of one sentence, you can compare it with the meaning of another sentence. That’s how you match and classify.
The architecture/dataflow
I like my Google Sheets, so naturally, that’s where I start.
Replicate has a sentence transformer model already deployed and ready to use as an API.
A bit of a Python script to handle the data and a Google Storage Bucket to store/retrieve the embedding.
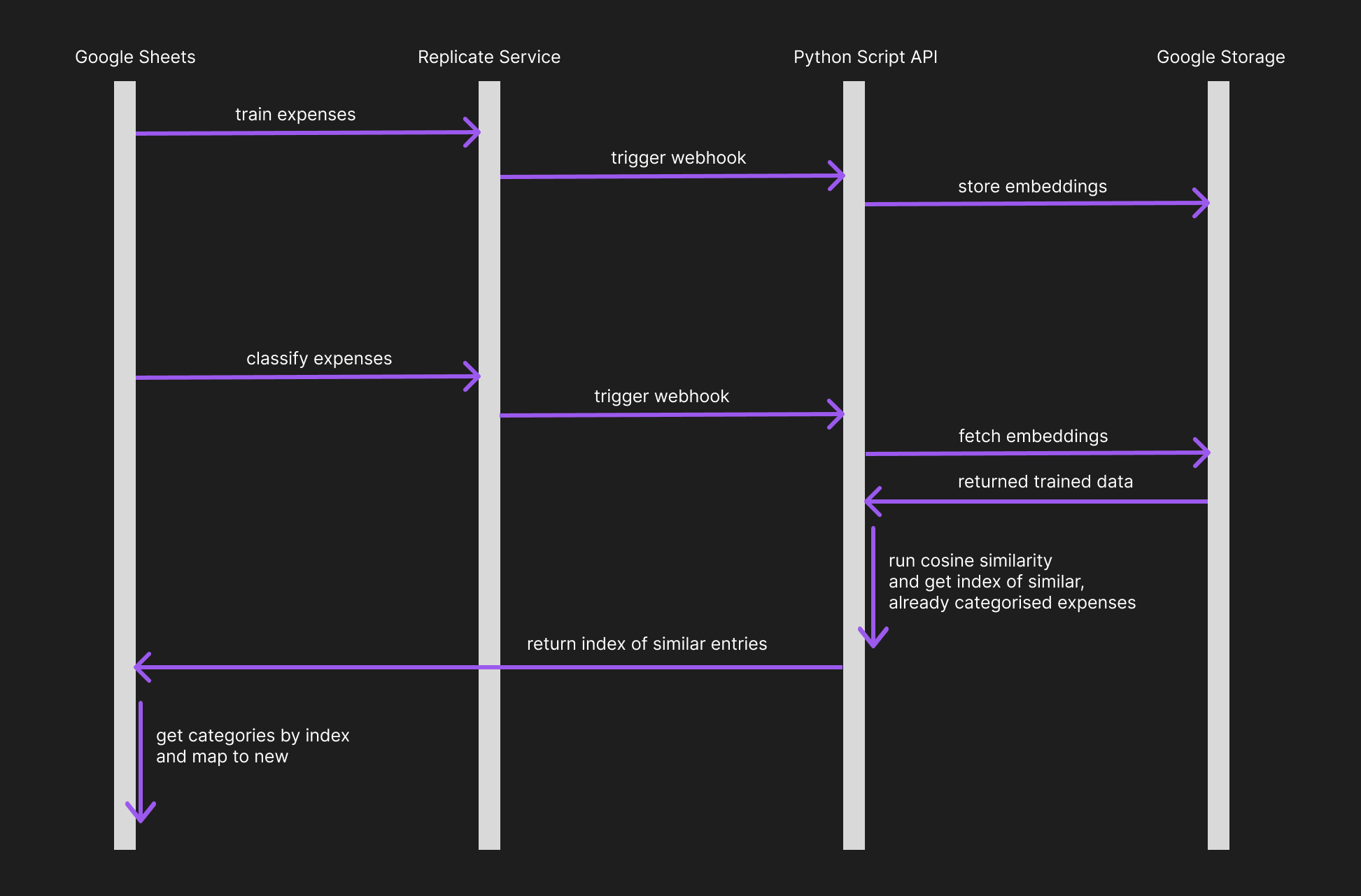
For the user, there are two steps to this:
The training, means you send in all of your old, already classified expenses, turn them into embeddings and save them.
The classifying, where the new expenses are turned into embeddings and the meaning of each is compared with the old expenses stored in the bucket.
Then send the matched data to the sheet once it’s completed. All that needs to be done from here is to get the category from the existing expense.
My prototype
The fully working app is in action.
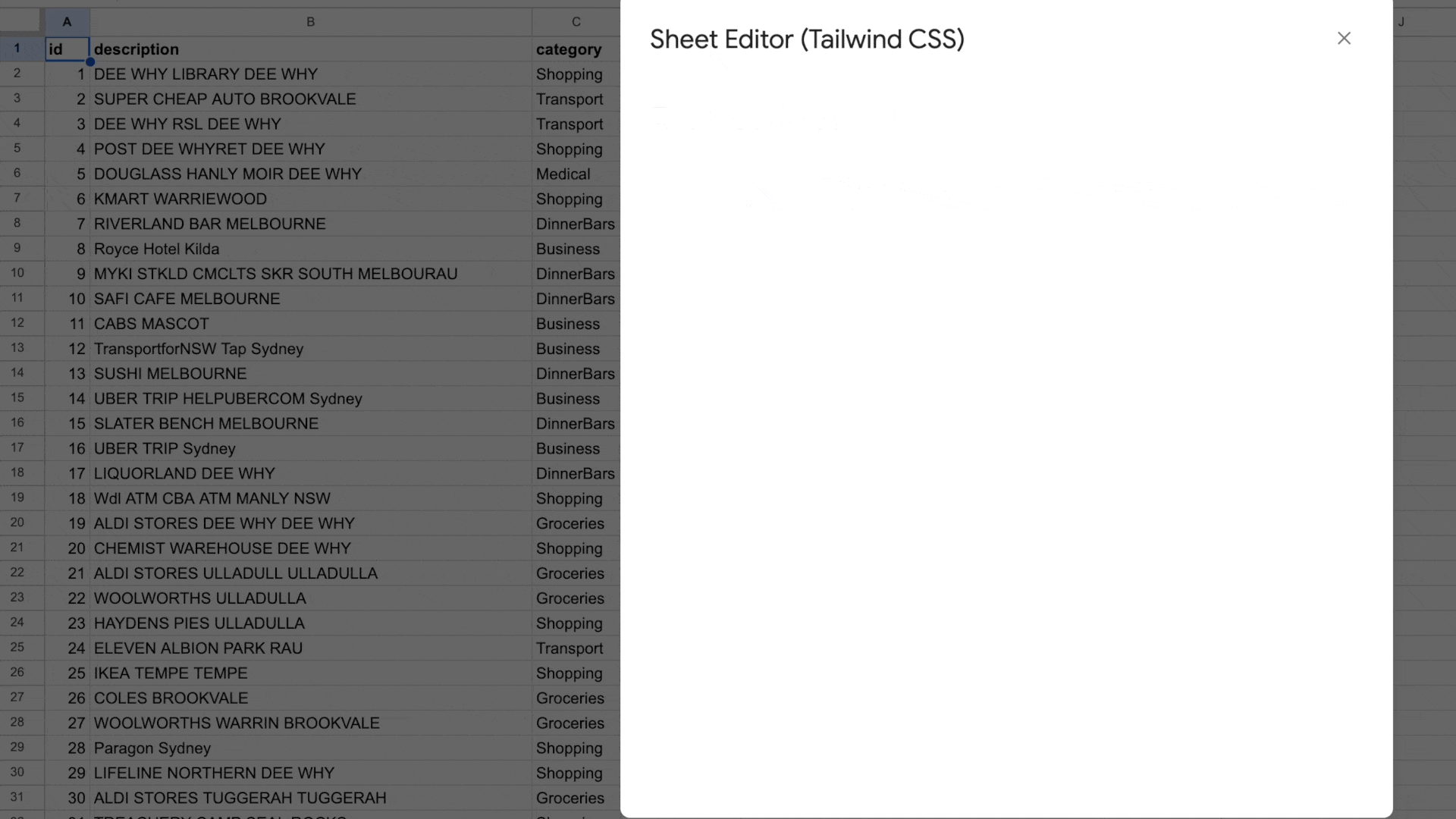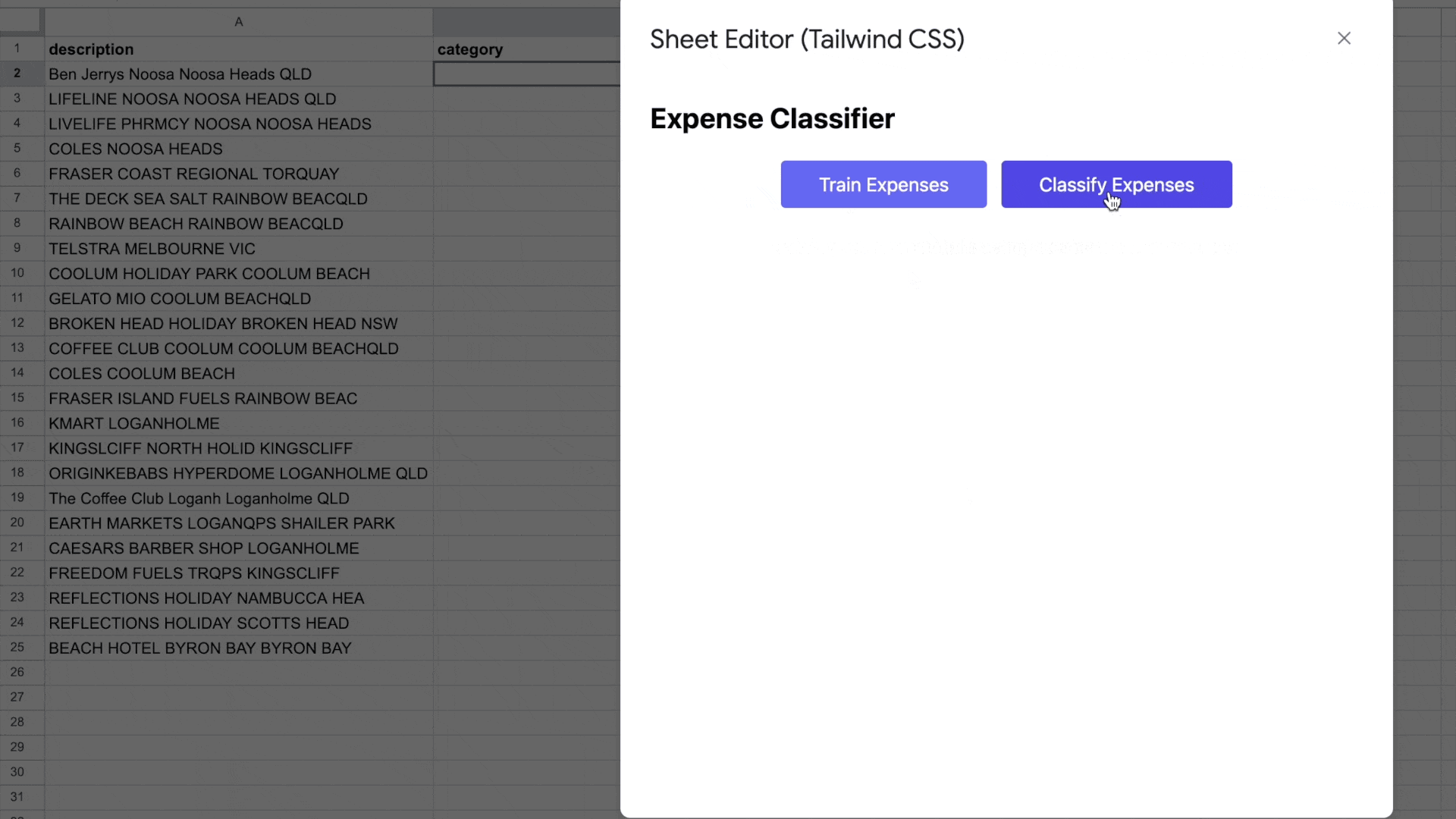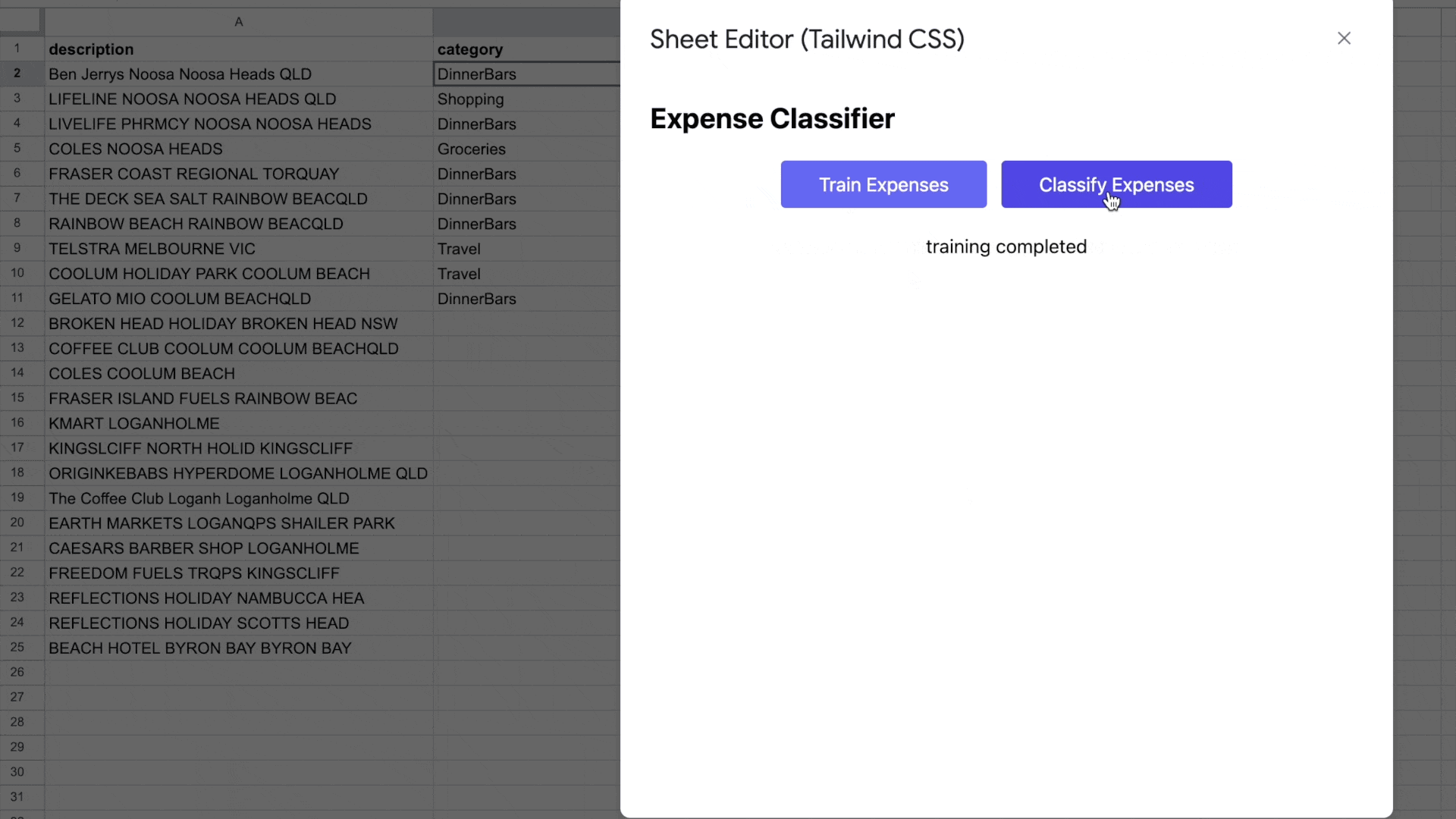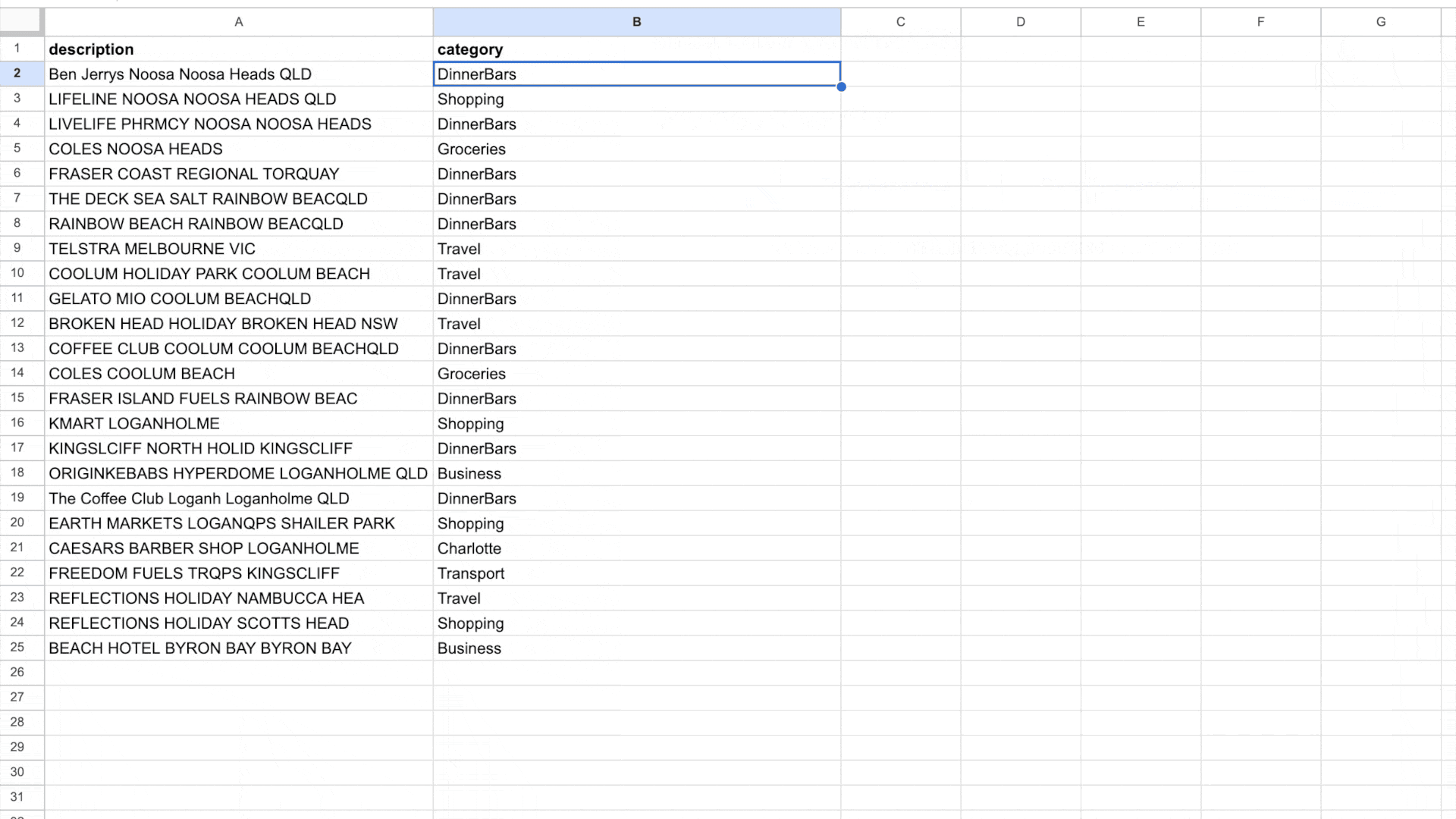
What is next, is to hook this into my spreadsheet, to ensure I can use it every month. This then hopefully makes my life easier.
Once tested and I have a good flow, I’d like to make this available to others.
Next Steps
I’d like to turn this into an extension that people can install into their Google Sheets.
For this, I need to solve a couple of problems around scalability:
how do I call the API of an individual Google Sheet, to send the data back?
how do I store the embedding data of individuals and protect personal data?
how do I clean the training data and remove as many duplicates as possible (smaller dataset = faster processing time)?
how much will it cost to run this on replicate?