Building an Expense classification app with Python and NextJS
A small step to fuck you money

In ‘Fuck you money doesn’t mean you need to be rich’, I walked through my thoughts on saving up time and gaining financial independence.
The point is being aware of the two parameters; savings and expenses and how they impact the free time you have at your disposal.
Arguably, the key to fuck your money is knowing your expenses. Tracking them, however, is an annoying topic and nobody really wants to spend a lot of time on it.
Most banking apps help, but the data is kind of temporary (they don’t store it forever), non-transferable (change your bank and it’s lost) and often not very customisable (adding expense classes often doesn’t work).
If you’re serious about fuck you money though, you better start taking care. Knowing what you earn and spend is the first step.
I’ve been using a spreadsheet, with rules-based classification for a couple of years now and thought I’d upgrade to something more sophisticated now that AI is all the rage.
The goal is to replace the spreadsheet with something easier, less annoying. In this post, I want to go through one part of this upgrade. The expense classification part. In future posts, I want to add bits and pieces until it becomes a full-blown app to replace the sheet. I’m not going to worry about the end goal just yet, but will start building away.
The architecture is simple. A Python backend using Flask to run within a Vercel Serverless Function. Nextjs and React, then are the front end.

The App
True to How to build a prototype, I’ll start with copy, paste, and adjust. Don’t reinvent the wheel. Vercel has a ton of great templates. I used this Nextjs and Flask starter.
The structure looks like this:
I then added two components <UserInput> and <ExpenseTable> where UserInput will be the main part of the screen.
"use client";
import { useState } from "react";
import { Formik, Form } from "formik";
import ExpenseTable from "./ExpenseTable";
export default function UserInput() {
const [initialValues, setInititalValues] = useState({
filePath: "",
expenses: [],
});
const handleUpdateClasses = (values) => {
if (values) {
const requestBody = values.expenses
fetch("/api/retrain", {
method: "POST",
body: JSON.stringify(requestBody),
headers: {
"Content-Type": "application/json",
},
})
.then((response) => response.json())
.then((data) => {
console.log("Successfully retrained based on user inputs");
})
.catch((error) => {
console.error(error);
});
}
};
const handleExportData = (values) => {
if (values) {
const requestBody = values.expenses
fetch("/api/convertToCSV", {
method: "POST",
body: JSON.stringify(requestBody),
headers: {
"Content-Type": "application/json",
},
})
.then((response) => response.text())
.then((csvData) => {
const csvFile = new Blob([csvData], { type: "text/csv" });
const csvURL = URL.createObjectURL(csvFile);
const downloadLink = document.createElement("a");
downloadLink.href = csvURL;
downloadLink.download = "exported_data.csv";
downloadLink.click();
URL.revokeObjectURL(csvURL);
console.log("CSV file exported successfully");
})
.catch((error) => {
console.error(error);
});
}
};
const submitData = async (values, { resetForm, setSubmitting }) => {
setSubmitting(true);
if (values) {
const formData = new FormData();
formData.append("file", values.filePath);
fetch("/api/classify", {
method: "POST",
body: formData,
})
.then((response) => response.json())
.then((data) => {
setInititalValues({ filePath: values.filePath, expenses: data });
})
.catch((error) => {
console.error(error);
});
}
setSubmitting(false);
};
return (
<div className="flex flex-col">
<Formik
initialValues={initialValues}
onSubmit={submitData}
enableReinitialize
>
{({ isSubmitting, setFieldValue, values }) => (
<Form>
<div className="flex flex-col">
<label htmlFor="fileUpload" className="block mb-4">
Upload new transactions to be classified:
</label>
<input
id="file"
name="file"
type="file"
onChange={(event) => {
setFieldValue("filePath", event.currentTarget.files[0]);
}}
/>
<div className="flex gap-4">
<button
type="submit"
className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded"
>
Classify
</button>
<button
type="button"
className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded"
onClick={() => handleUpdateClasses(values)}
>
Update Categories
</button>
<button
type="button"
className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded"
onClick={() => handleExportData(values)}
>
Export New Data
</button>
</div>
</div>
<ExpenseTable data={values?.expenses} />
</Form>
)}
</Formik>
</div>
);
}
The table showing the uploaded expenses and letting the user classify is built as follows:
import React, { useState } from "react";
import { Field, FieldArray } from 'formik'
const ExpenseTable = ({ data }) => {
const [selectedCategories, setSelectedCategories] = useState({});
return (
<div className="relative overflow-x-auto bg-white shadow-md rounded my-6 text-xs">
<FieldArray
name="expenses"
render={(arrayHelpers) => (
<>
<table className="max-w-screen-2xl w-full table-auto overflow-auto">
<thead>
<tr className="bg-gray-200 text-gray-600 uppercase text-xs leading-normal">
<th className="py-3 px-6 text-left text-xs">Date</th>
<th className="py-3 px-6 text-left">Amount</th>
<th className="py-3 px-6 text-left">Narrative</th>
<th className="py-3 px-6 text-left">Categories</th>
</tr>
</thead>
<tbody className="text-gray-600 text-xs font-light">
{data.map((item, index) => (
<tr
key={index}
className={
(index % 2 === 0 ? "bg-white" : "bg-gray-50") +
" border-b border-gray-200"
}
>
<td className="py-2 px-3 text-left">{item?.Date}</td>
<td className="py-2 px-3 text-left">{item?.Amount}</td>
<td className="py-2 px-3 text-left">{item?.Narrative}</td>
<td className="py-2 px-3 text-left">
<Field
as="select"
name={`expenses.${index}.Categories`}
>
<option value={null}>none</option>
<option value="Groceries">Groceries</option>
<option value="Shopping">Shopping</option>
<option value="DinnerBars">Dinner/Bars</option>
<option value="Medical">Medical</option>
<option value="Transport">Transport</option>
<option value="Utility">Utility</option>
<option value="Travel">Travel</option>
<option value="Business">Business</option>
<option value="Living">Living</option>
</Field>
</td>
</tr>
))}
</tbody>
</table>
</>
)}
/>
</div>
);
};
export default ExpenseTable;
You can see that all this is a basic Formik form and a few buttons.
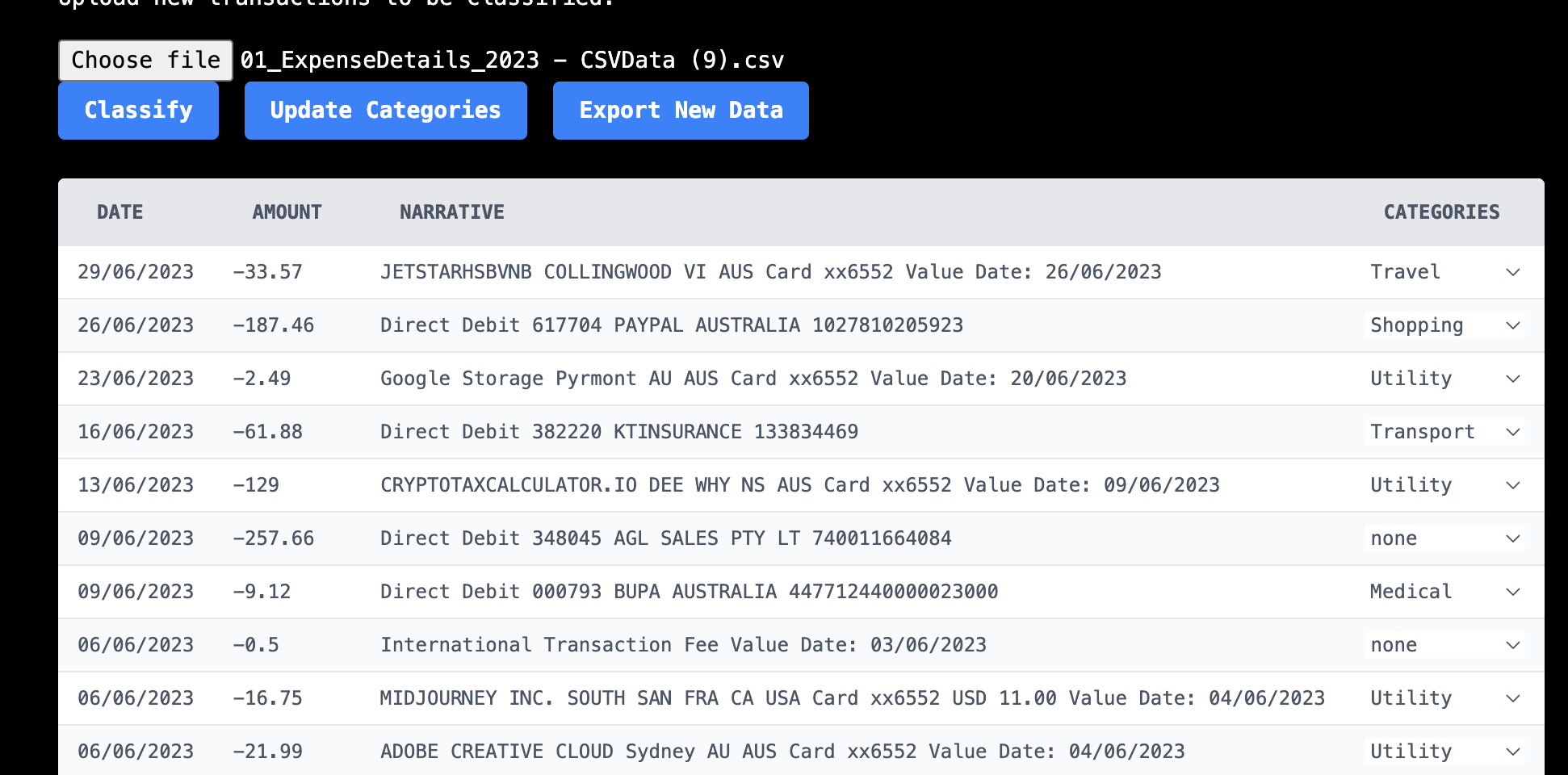
A user walks through these steps:
Upload a CSV file (currently needs to be in the right format)
Hit classify (which calls the Python API and applies the pre-trained model to the new dataset)
Correct any mistakes by selecting a new category in the dropdown
Hit update categories to retrain the model with a newly classified dataset
Export data to add it to whatever tool/sheet you use to classify all your expenses
Let’s have a look at the API next.
Bank statement classification
I started off with a tutorial from here. It’s using BERT and Python to add and categorise the transactions based on a trained language model and your own training data. All it needs is the bank statement descriptions.
The tutorial was really useful to do an initial breakthrough, but in order to use it in an app, I had to rewrite the code to modular functions (all code here):
import datetime
from io import StringIO
import json
import logging
from flask import Flask, request, make_response
import nltk
from nltk.tokenize import word_tokenize
import re
import pandas as pd
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# from flask_cors import CORS
app = Flask(__name__)
# CORS(app)
logging.basicConfig(level=logging.DEBUG)
@app.route("/api/classify", methods=["POST"])
def classify():
file = request.files["file"]
app.logger.debug(f"Received file: {file}")
file_contents = file.read().decode("utf-8")
csv_data = StringIO(file_contents)
df_unclassified_data = pd.read_csv(
csv_data, header=None, names=["Date", "Amount", "Narrative", "old"]
)
df_unclassified_data.drop("old", axis=1, inplace=True)
# print(df_unclassified_data)
trained_embeddings_BERT = np.load("trained_embeddings.npy")
classified_file_path = "all_expenses_classified.csv"
df_classified_data = pd.read_csv(classified_file_path)
print("Found trained data")
output = classify_expenses(
df_unclassified_data, trained_embeddings_BERT, df_classified_data
)
df_output = pd.DataFrame.from_dict(output)
# Convert the DataFrame to JSON
json_data = df_output.to_json(orient="records")
response = make_response(json_data)
response.headers["Content-Type"] = "application/json"
# Return the JSON data
return json_data
@app.route("/api/convertToCSV", methods=["POST"])
def convertToCSV():
data = request.json
df = pd.DataFrame(data)
csv_data = df.to_csv(index=False)
response = make_response(csv_data)
response.headers["Content-Disposition"] = "attachment; filename=exported_data.csv"
response.headers["Content-type"] = "text/csv"
return response
@app.route("/api/retrain", methods=["POST"])
def retrain():
try:
data = request.json
df_reclassified = pd.DataFrame(data)
df_reclassified = df_reclassified.rename(columns={"Amount": "Debit Amount"})
classified_file_path = "all_expenses_classified.csv"
df_classified_data = pd.read_csv(classified_file_path)
df_combined = pd.concat(
[df_classified_data, df_reclassified], ignore_index=True
)
df_combined = df_combined.drop_duplicates()
text_descriptions = df_combined["Narrative"]
text_BERT = text_descriptions.apply(lambda x: clean_text_BERT(x))
bert_input = text_BERT.tolist()
model = SentenceTransformer("paraphrase-mpnet-base-v2")
embeddings = model.encode(bert_input, show_progress_bar=True)
embedding_BERT = np.array(embeddings)
np.save("trained_embeddings.npy", embedding_BERT)
df_combined.to_csv("all_expenses_classified.csv", index=False)
response = make_response({"message": "Success: Retraining completed successfully!"})
response.headers["Content-Type"] = "application/json"
return response
except Exception as e:
response = make_response({"error": str(e)})
response = make_response({"error": ''})
response.headers["Content-Type"] = "application/json"
return response
def clean_text_BERT(text):
text = text.lower()
text = re.sub(
r"[^\\w\\s]|https?://\\S+|www\\.\\S+|https?:/\\S+|[^\\x00-\\x7F]+|\\d+",
"",
str(text).strip(),
)
text_list = word_tokenize(text)
result = " ".join(text_list)
return result
def classify_expenses(df_unclassified_data, trained_embeddings_BERT, df_training_data):
desc_new_data = df_unclassified_data["Narrative"]
amount = df_unclassified_data["Amount"]
date = df_unclassified_data["Date"]
text_BERT = desc_new_data.apply(lambda x: clean_text_BERT(x))
bert_input = text_BERT.tolist()
model = SentenceTransformer("paraphrase-mpnet-base-v2")
embeddings_new = model.encode(bert_input, show_progress_bar=True)
embedding_BERT_new = np.array(embeddings_new)
similarity_new_data = cosine_similarity(embedding_BERT_new, trained_embeddings_BERT)
similarity_df = pd.DataFrame(similarity_new_data)
index_similarity = similarity_df.idxmax(axis=1)
data_inspect = df_training_data.iloc[index_similarity, :].reset_index(drop=True)
annotation = data_inspect["Categories"]
d_output = {
"Date": date,
"Amount": amount,
"Narrative": desc_new_data,
"Categories": annotation,
}
return d_output
def run_test_classify(test_file_name):
with app.test_client() as client:
with open(test_file_name, "rb") as file:
response = client.post("/api/classify", data={"file": file})
# print(response.get_json())
def run_test_retrain(test_data):
with app.test_client() as client:
response = client.post("/api/retrain", json=test_data)
print(response.get_json())
if __name__ == "__main__":
app.run()
# test_file_name = "new_expenses.csv"
# run_test_classify(test_file_name)
# test_data = [
# {
# "Date": "27/05/2023",
# "Amount": -27.88,
# "Narrative": "CRUISIN MOTORHOMES CAMBRIDGE AUS Card xx6552 Value Date: 25/05/2023",
# "Categories": "Travel",
# },
# {
# "Date": "26/05/2023",
# "Amount": -5.44,
# "Narrative": "TRANSPORTFORNSW TAP SYDNEY AUS Card xx0033 Value Date: 23/05/2023",
# "Categories": "Transport",
# },
# {
# "Date": "24/05/2023",
# "Amount": -7.58,
# "Narrative": "Girdlers Dee Why Dee Why NS AUS Card xx6552 Value Date: 22/05/2023",
# "Categories": "DinnerBars",
# },
# ]
# run_test_retrain(test_data)
The above API consists of two main functions:
classify: takes the uploaded file, extracts the transaction description, loads the pre-trained model and matches categories.
retrain: takes a categorised dataset and appends it to the total set of transactions to then retrain the dataset.
The remaining functions are for testing and exporting the trained data of that month into whatever solution you use to keep track of all your expenses (I’m using something like this).
For it all to work, you will need to run it with retraining for the very first time with a month of data just to create that initial training data set.
Next steps
This is obviously barebones basic and won’t be able to replace what I have yet. But it is a little modular part that I can already use every month to classify my expenses.
Next, I’d love to get into storing the data somewhere and adding some features to analyse the transactions into something meaningful. Perhaps also some more generic way of handling input CSV files.
Stay tuned.